Operating System Lab
Operating system lab
Quick Links
- Experiment 1
- Experiment 2
- Experiment 3
- Experiment 4
- Experiment 5
- Experiment 6
- Experiment 7
- Experiment 8
- Experiment 9
- Experiment 10
Theory:
- An operating system (OS) is software that manages and handles the hardware and software resources of a system. It provides intrection between users of computers and computer hardware.
- An operating system is responsible for managing and controlling all the activities and sharing of computer resources.
- An operating system is a low-level software that includes all the basic functions like processor management, memory management, error detection, etc.
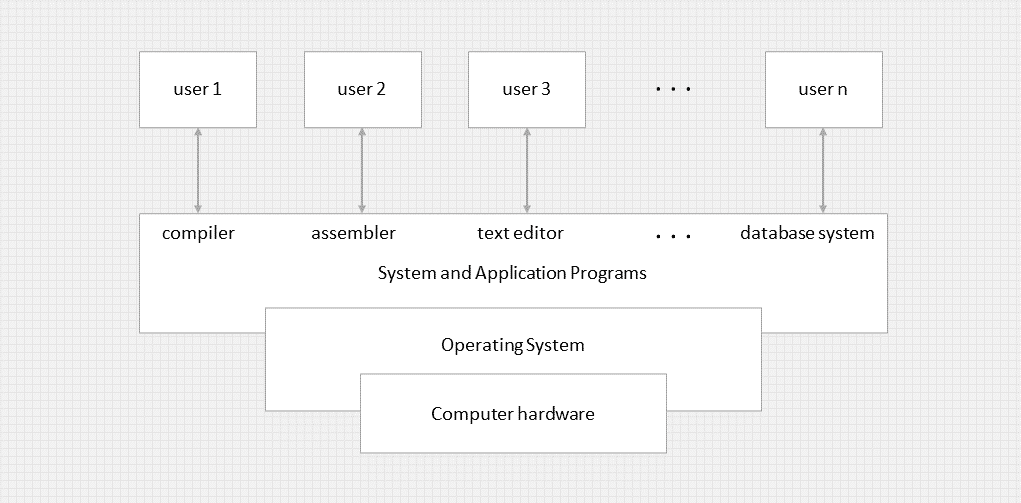
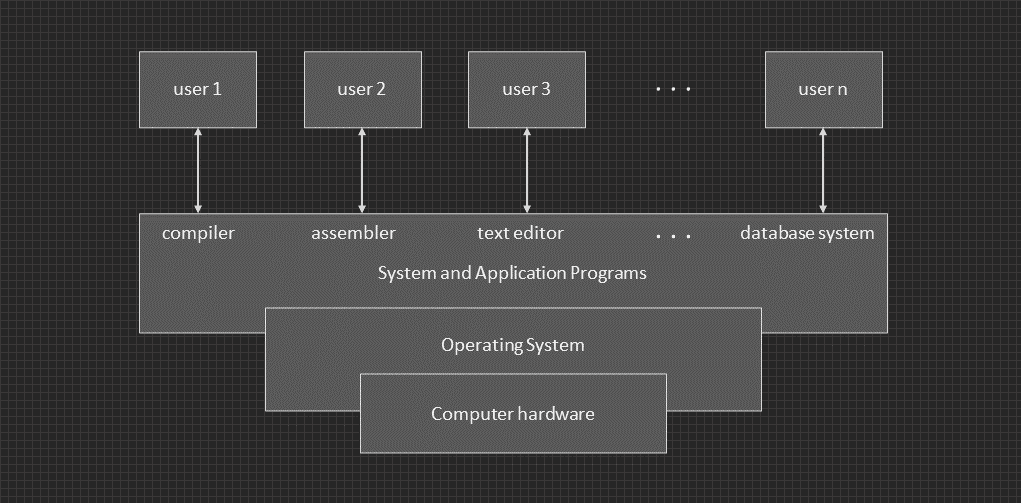
Abstract view of a computer system.
Hardware requirements
- Processor: 1 GHz or faster processor
- RAM: 1 GB for 32-bit or 2 GB for 64-bit
- Storage space: 16 GB for 32-bit OS or 20 GB for 64-bit OS.
- Display: 800 x 6009 with WDDM driver
Software requirements
- Graphics Card: Direct X9 or later with WDDM 1.0 driver
Hardware requirements
- Processor: Minimum of 1 GHz processor
- RAM: Minimum of 1 GB RAM
- Storage space: Minimum of 10 GB free disk space
Software requirements
- UNIX-compatible operating system, such as Sun Solaris, IBM AIX, HP-UX, etc.
- Compiler and development tools
- X Window System for graphical user interface
- Networking tools for network communication
Hardware Requirements:
- Processor: Minimum of 1 GHz processor
- RAM: Minimum of 1 GB RAM (2 GB or more recommended for better performance)
- Storage space: Minimum of 10 GB free disk space (20 GB or more recommended for better performance)
Software Requirements:
- Linux distribution, such as Ubuntu, Fedora, CentOS, Debian, etc.
- Graphical user interface
- Compiler and development tools
- Networking tools for network communication
Hardware Requirements:
- Processor: Minimum of Pentium 233 MHz processor (300 MHz or higher)
- RAM: Minimum of 64 MB RAM (128 MB or higher)
- Storage space: Minimum of 1.5 GB free disk space
Software Requirements:
- Windows XP operating system
- DirectX 9 graphics device with WDDM driver (optional for graphical user interface)
- Networking tools for network communication (optional)
Hardware Requirements:
- Processor: Minimum of 1 GHz processor (1 GHz or higher)
- RAM: Minimum of 1 GB RAM (2 GB or higher)
- Storage space: Minimum of 16 GB free disk space (20 GB or higher)
Software Requirements:
- Windows 7 or Windows 8 operating system
- DirectX 9 graphics device with WDDM 1.0 or higher driver (optional for graphical user interface)
- Networking tools for network communication
- Process Management
- File Management
- Input/Output System Calls
Process Management: Process management uses certain system calls. They are explained below.
fork(): system call is used to create a new process.exec(): system call is used to run a new program.wait(): system call is used to make the process to wait.exit(): system call is used to terminate the process.getpid(): system call is used to find the unique process id.getppid(): system call is used to find the parent process id.nice(): system call is used to bias the currently running process property.
Example program for example of fork()
#include <stdio.h>
#include <sys/types.h>
main()
{
int pid;
pid = fork();
if (pid == 0)
{
printf("id of the child process is=%d\n", getpid());
printf("id of the parent process is=%d\n", getppid());
}
else
{
printf("id of the parent process is=%d\n", getpid());
printf("id of the parent of parent process is=%d\n", getppid());
}
}OUTPUT
id of the parent process is=8971
id of the parent of parent process is=8970
id of the child process is=8972
id of the parent process is=8971File Management: There are four system calls for file management,
open(): system call is used to know the file descriptor of user-created files. Since read and write use file descriptor as their 1st parameter so to know the file descriptoropen()system call is used.read(): system call is used to read the content from the file. It can also be used to read the input from the keyboard by specifying the 0 as file descriptor.write(): system call is used to write the content to the file.close(): system call is used to close the opened file, it tells the operating system that you are done with the file and close the file.
Example program for file management
#include <unistd.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <stdio.h>
int main()
{
int n, fd;
char buff[50];
printf("Enter text to write in the file:\n");
n = read(0, buff, 50);
fd = open("file", O_CREAT | O_RDWR, 0777);
write(fd, buff, n);
write(1, buff, n);
int close(int fd);
return 0;
}
OUTPUT
Enter text to write in the file:
hi how r u?
hi how r u?Input/Output System Calls: Basically there are total 5 types of I/O system calls:
create(): Used to Create a new empty file.open(): Used to Open the file for reading, writing or both.close(): Tells the operating system you are done with a file descriptor and Close the filewhich pointed by fd.read(): From the file indicated by the file descriptor fd, theread()function reads bytesof input into the memory area indicated by buf.write(): Writes bytes from buf to the file or socket associated with fd.
Example program for Input/output System Calls
#include <stdio.h>
#include <unistd.h>
int main()
{
char buffer[100];
int n;
// Read input from the user
write(STDOUT_FILENO, "Enter a message: ", 17);
n = read(STDIN_FILENO, buffer, 100);
// Write the input back to the user
write(STDOUT_FILENO, "You entered: ", 13);
write(STDOUT_FILENO, buffer, n);
return 0;
}OUTPUT
Enter a message: helo
You entered: helo- SJF
- FCFS
Theory:
- CPU scheduling is a core operating system function that manages the allocation of CPU resources to processes.
- Its primary goal is to maximize system throughput, minimize response time, and ensure fairness among processes.
Scheduling Criteria:
- CPU Utilization: Maximizing CPU utilization ensures that the CPU is kept busy executing processes as much as possible.
- Throughput: Throughput measures the number of processes completed per unit of time, indicating system efficiency.
- Turnaround Time: Turnaround time is the total time taken to execute a process, including waiting time and execution time.
- Waiting Time: Waiting time is the total time a process spends waiting in the ready queue before getting CPU time.
- Response Time: Response time is the time taken from submitting a request until the first response is produced.
Sortest Job First (SJF): SJF scheduling selects the processs with the smallest execution time next. This scheduling algorithm can be preemitive or non-premptive.
#include <stdio.h>
void main()
{
int bt[20], p[20], wt[20], tat[20], i, j, n, total = 0, pos, temp;
// bt-Burst Time // wt-Waiting Time // tat-Turn Around Time //pos-position
float avg_wt, avg_tat;
printf("Enter number of process:");
scanf("%d", &n);
printf("\nEnter Burst Time:\n");
for (i = 0; i < n; i++)
{
printf("p%d:", i + 1);
scanf("%d", &bt[i]);
p[i] = i + 1; // contains process number
}
// sorting burst time in ascending order using selection sort
for (i = 0; i < n; i++)
{
pos = i;
for (j = i + 1; j < n; j++)
{
if (bt[j] < bt[pos])
pos = j;
}
temp = bt[i];
bt[i] = bt[pos];
bt[pos] = temp;
temp = p[i];
p[i] = p[pos];
p[pos] = temp;
}
wt[0] = 0; // waiting time for first process will be zero
// calculate waiting time
for (i = 1; i < n; i++)
{
wt[i] = 0;
for (j = 0; j < i; j++)
wt[i] += bt[j];
total += wt[i];
}
avg_wt = (float)total / n; // average waiting time
total = 0;
printf("\nProcess\t Burst Time \tWaiting Time\tTurnaround Time");
for (i = 0; i < n; i++)
{
tat[i] = bt[i] + wt[i]; // calculate turnaround time
total += tat[i];
printf("\np%d\t\t %d\t\t %d\t\t%d", p[i], bt[i], wt[i], tat[i]);
}
avg_tat = (float)total / n; // average turnaround time
printf("\n\nAverage Waiting Time=%f", avg_wt);
printf("\nAverage Turnaround Time=%f\n", avg_tat);
}Enter number of process:6
Enter Burst Time:
p1:1
p2:5
p3:9
p4:7
p5:4
p6:8
Process Burst Time Waiting Time Turnaround Time
p1 1 0 1
p5 4 1 5
p2 5 5 10
p4 7 10 17
p6 8 17 25
p3 9 25 34
Average Waiting Time=9.666667
Average Turnaround Time=15.333333 First Come First Search (FCFS): FCFS scheduling selects the process that arrives first. It's a non-preemitive scheduling algorithm.
#include <stdio.h>
int main()
{
int n, bt[30], wait_t[30], turn_ar_t[30], av_wt_t = 0, avturn_ar_t = 0, i, j;
// the maximum process that be used to calculate is specified.
printf("Please enter the total number of processes(maximum 30): ");
scanf("%d", &n);
printf("\nEnter The Process Burst Time\n");
for (i = 0; i < n; i++) // burst time for every process will be taken as input
{
printf("P[%d]:", i + 1);
scanf("%d", &bt[i]);
}
wait_t[0] = 0;
for (i = 1; i < n; i++)
{
wait_t[i] = 0;
for (j = 0; j < i; j++)
wait_t[i] += bt[j];
}
printf("\nProcess\t\tBurst Time\tWaiting Time\tTurnaround Time");
for (i = 0; i < n; i++)
{
turn_ar_t[i] = bt[i] + wait_t[i];
av_wt_t += wait_t[i];
avturn_ar_t += turn_ar_t[i];
printf("\nP[%d]\t\t%d\t\t\t%d\t\t\t\t%d", i + 1, bt[i], wait_t[i], turn_ar_t[i]);
}
av_wt_t /= i;
avturn_ar_t /= i; // average calculation is done here
printf("\nAverage Waiting Time=%d", av_wt_t);
printf("\nAverage Turnaround Time=%d", avturn_ar_t);
return 0;
}Please enter the total number of processes(maximum 30): 5
Enter The Process Burst Time
P[1]:4
P[2]:6
P[3]:2
P[4]:1
P[5]:9
Process Burst Time Waiting Time Turnaround Time
P[1] 4 0 4
P[2] 6 4 10
P[3] 2 10 12
P[4] 1 12 13
P[5] 9 13 22
Average Waiting Time=7
Average Turnaround Time=12- Priority Scheduling
- Round Robin
Theory:
Preemptive Scheduling: Preemptive scheduling is used when a process switches from the running state to the ready state or from the waiting state to the ready state.
The resources are allocated to the process for a limited amount of time and then taken away, and the process is again placed back in the ready queue if that process still has CPU burst time remaining.
- Round Robin: Round Robin is a CPU scheduling algorithm where each process is cyclically assigned a fixed time slot. It is the preemptive version of the First come First Serve CPU Scheduling algorithm.
Algorithm
- Step 1: Start the process.
- Step 2: Accept the number of processes in the ready Queue and time quantum.
- Step 3: For each process in the ready Queue, assign the process and accept the CPU burst time.
- Step 4: Each process runs for a predefined time quantum.
- Step 5: If a process finishes execution within the time quantum, it is removed from the queue. If a process does not finish within the time quantum, it is pre-empted, and put at the end of the queue to await further execution.
- Step 6: When a process is preempted, the CPU switches to the next process in the queue.
- Step 7: Continue this process of executing each process for its time quantum until all processes have completed their execution.
- Step 8: Stop.
#include <stdio.h>
void round_robin(int processes[], int n, int burst_times[], int quantum)
{
int remaining_burst_times[n];
int waiting_times[n];
int turnaround_times[n];
int total_waiting_time = 0;
int total_turnaround_time = 0;
int time = 0;
int done;
for (int i = 0; i < n; i++)
{
remaining_burst_times[i] = burst_times[i];
waiting_times[i] = 0;
}
while (1)
{
done = 1;
for (int i = 0; i < n; i++)
{
if (remaining_burst_times[i] > 0)
{
done = 0;
if (remaining_burst_times[i] > quantum)
{
time += quantum;
remaining_burst_times[i] -= quantum;
}
else
{
time += remaining_burst_times[i];
waiting_times[i] = time - burst_times[i];
remaining_burst_times[i] = 0;
}
}
}
if (done == 1)
break;
}
for (int i = 0; i < n; i++)
{
turnaround_times[i] = burst_times[i] + waiting_times[i];
total_waiting_time += waiting_times[i];
total_turnaround_time += turnaround_times[i];
}
printf("Process\tBurst Time\tTurnaround Time\tWaiting Time\n");
for (int i = 0; i < n; i++)
{
printf("P%d\t%d\t\t%d\t\t %d\n", processes[i], burst_times[i], turnaround_times[i],
waiting_times[i]);
}
printf("Average Turnaround Time: %.2f\n", (float)total_turnaround_time / n);
printf("Average Waiting Time: %.2f\n", (float)total_waiting_time / n);
}
int main()
{
int n, quantum;
printf("Enter the number of processes: ");
scanf("%d", &n);
int processes[n];
int burst_times[n];
printf("Enter burst time for the following process:\n");
for (int i = 0; i < n; i++)
{
processes[i] = i + 1;
printf("P%d: ", i + 1);
scanf("%d", &burst_times[i]);
}
printf("Enter the quantum time: ");
scanf("%d", &quantum);
round_robin(processes, n, burst_times, quantum);
return 0;
}
Enter the number of processes: 4
Enter burst time for the following process:
P1: 6
P2: 8
P3: 9
P4: 2
Enter the quantum time: 3
Process Burst Time Turnaround Time Waiting Time
P1 6 14 8
P2 8 22 14
P3 9 25 16
P4 2 11 9
Average Turnaround Time: 18.00
Average Waiting Time: 11.75 - Priority Scheduling Algorithm: Preemptive Priority CPU Scheduling Algorithm is a pre-emptive method of CPU scheduling algorithm that works based on the priority of a process. In this algorithm, the scheduler schedules the tasks to work as per the priority, which means that a higher priority process should be executed first.
Algorithm
- Step-1: Select the first process whose arrival time will be 0, we need to select that process because that process is only executing at time t=0.
- Step-2: Check the priority of the next available process. Here we need to check for 3 conditions.
if priority(current process) > priority(prior process): then execute the current process.if priority(current process) < priority(prior process): then execute the prior process.if priority(current process) = priority(prior process): then execute the process which arrives first i.e., arrival time should be first.- Step-3: Repeat Step-2 until it reaches the final process.
- Step-4: When it reaches the final process, choose the process which is having the highest priority & execute it. Repeat the same step until all processes complete their execution.
#include <stdio.h>
typedef struct
{
int process_id;
int burst_time;
int priority;
} Process;
void priority_scheduling(Process processes[], int n)
{
int waiting_times[n];
int turnaround_times[n];
int total_waiting_time = 0;
int total_turnaround_time = 0;
for (int i = 0; i < n - 1; i++)
{
for (int j = i + 1; j < n; j++)
{
if (processes[i].priority > processes[j].priority)
{
Process temp = processes[i];
processes[i] = processes[j];
processes[j] = temp;
}
}
}
waiting_times[0] = 0;
for (int i = 1; i < n; i++)
{
waiting_times[i] = waiting_times[i - 1] + processes[i - 1].burst_time;
}
for (int i = 0; i < n; i++)
{
turnaround_times[i] = processes[i].burst_time + waiting_times[i];
total_waiting_time += waiting_times[i];
total_turnaround_time += turnaround_times[i];
}
printf("Process\tBurst Time\tPriority\tTurnaround Time\tWaiting Time\n");
for (int i = 0; i < n; i++)
{
printf("P%d\t%d\t\t%d\t\t %d\t\t%d\n", processes[i].process_id, processes[i].burst_time,
processes[i].priority, turnaround_times[i], waiting_times[i]);
}
printf("Average Waiting Time: %.2f\n", (float)total_waiting_time / n);
printf("Average Turnaround Time: %.2f\n", (float)total_turnaround_time / n);
}
int main()
{
int n;
printf("Enter the number of processes: ");
scanf("%d", &n);
Process processes[n];
printf("Enter burst time for the following process:\n");
for (int i = 0; i < n; i++)
{
processes[i].process_id = i + 1;
printf("P%d: ", i + 1);
scanf("%d", &processes[i].burst_time);
}
printf("Enter priority for the following process:\n");
for (int i = 0; i < n; i++)
{
processes[i].process_id = i + 1;
printf("P%d: ", i + 1);
scanf("%d", &processes[i].priority);
}
priority_scheduling(processes, n);
return 0;
}Enter the number of processes: 4
Enter burst time for the following process:
P1: 4
P2: 6
P3: 3
P4: 8
Enter priority for the following process:
P1: 4
P2: 7
P3: 2
P4: 1
Process Burst Time Priority Turnaround Time Waiting Time
P4 8 1 8 0
P3 3 2 11 8
P1 4 4 15 11
P2 6 7 21 15
Average Waiting Time: 8.50
Average Turnaround Time: 13.75Theory:
Banker's Algorithm: The Banker's algorithm is a resource allocation and deadlock avoidance algorithm that tests for safety by simulating the allocation for predetermined maximum possible amounts of all resources, then makes an safe state check to test for possible activities, before deciding whether allocation should be allowed to continue.
Following Data structures are used to implement the Banker's Algorithm: Let n be the number of processes in the system and m be the number of resources types.
Available:
- It is a 1-d array of size
mindicating the number of available resources of each type. Available[j] = kmeans there arekinstances of resource type Rj
Max:
- It is a 2-d array of size
n*mthat defines the maximum demand of each process in a system. Max[i][j] = kmeans process Pi may request at mostkinstances of resource typeRj.
Allocation:
- It is a 2-d array of size
n*mthat defines the number of resources of each type currently allocated to each process. Allocation[i][j] = kmeans processPiis currently allocatedkinstances of resource typeRj.
Need:
-
It is a 2-d array of size
n*mthat indicates the remaining resource need of each process. -
Need[i][j] = kmeans processPicurrently needkinstances of resource typeRjfor its execution. -
Need[i][j] = Max[i][j] - Allocation[i][j] -
Allocation specifies the resources currently allocated to process Pi and Needi specifies the additional resources that process Pi may still request to complete its task. Banker's algorithm consists of Safety algorithm and Resource request algorithm.
Safety Algorithm:
- Step 1: Let Work and Finish be vectors of length
mandnrespectively.
Work = Available
Finish[ i ] = false;
for i=1, 2, 3, 4….n- Step 2: Find an i such that both
Finish[i] = falseNeed[i]<= Workif no such i exists goto step 4 - Step 3:
Work = Work + Allocation[i]Finish[ i ] = trueGo to Step 2. - Step 4:
if Finish [ i ] = truefor allithen the system is in a safe state
Resource-Request Algorithm: Let Request[i] be the request array for process Pi. Request[i][j] = k means process Pi wants k instances of resource type Rj. When a request for resources is made by process Pi, the following actions are taken:
- Step 1:
If Request[i]<= Need[i]Goto Step 2. Otherwise, raise an error condition, since the process has exceeded its maximum claim. - Step 2:
If Request[i]<= AvailableGoto Step 3; otherwise,Pimust wait, since the resources are not available. - Step 3: Have the system pretend to have allocated the requested resources to process
Piby modifying the state as follows:
Available = Available - Request[ i ]
Allocation[ i ] = Allocation[ i ] + Request[ i ]
Need[ i ] = Need[ i ] - Request[ i ] #include <stdio.h>
int main()
{
int n, m, i, j, k, alloc[20][20], max[20][20], avail[20];
printf("Enter the number of process: ");
scanf("%d", &n);
printf("Enter the number of resources: ");
scanf("%d", &m);
// Allocate Resources from the user
printf("Enter the Allocated Resources:\n");
for (i = 0; i < n; i++)
for (j = 0; j < m; j++)
{
printf("alloc[P%d][R%d]= ", i, j);
scanf("%d", &alloc[i][j]);
}
// Provide Max matrix from the user
printf("Enter the Max Resources:\n");
for (i = 0; i < n; i++)
for (j = 0; j < m; j++)
{
printf("max[P%d][R%d]: ", i, j);
scanf("%d", &max[i][j]);
}
// Define the Available Resources
printf("Enter the Available Resources:\n");
for (i = 0; i < m; i++)
{
printf("avail[R%d]: ", i);
scanf("%d", &avail[i]);
}
int f[n], ans[n], ind = 0;
for (k = 0; k < n; k++)
{
f[k] = 0;
}
// Calculate the need matrix
int need[n][m];
for (i = 0; i < n; i++)
{
for (j = 0; j < m; j++)
need[i][j] = max[i][j] - alloc[i][j];
}
// Find the Safe Sequence
int y = 0;
for (k = 0; k < 5; k++)
{
for (i = 0; i < n; i++)
{
if (f[i] == 0)
{
int flag = 0;
for (j = 0; j < m; j++)
{
if (need[i][j] > avail[j])
{
flag = 1;
break;
}
}
if (flag == 0)
{
ans[ind++] = i;
for (y = 0; y < m; y++)
avail[y] += alloc[i][y];
f[i] = 1;
}
}
}
}
int flag = 1;
// To check if sequence is Safe or Not
for (int i = 0; i < n; i++)
{
if (f[i] == 0)
{
flag = 0;
printf("The Following System is not safe");
break;
}
}
// Print the Safe Sequence
if (flag == 1)
{
printf("Following is the SAFE Sequence\n");
for (i = 0; i < n - 1; i++)
printf(" P%d ->", ans[i]);
printf(" P%d", ans[n - 1]);
}
return (0);
}Enter the number of process: 5
Enter the number of resources: 4
Enter the Allocated Resources:
alloc[P0][R0]: 0
alloc[P0][R1]: 0
alloc[P0][R2]: 1
alloc[P0][R3]: 2
alloc[P1][R0]: 1
alloc[P1][R1]: 0
alloc[P1][R2]: 0
alloc[P1][R3]: 0
alloc[P2][R0]: 1
alloc[P2][R1]: 3
alloc[P2][R2]: 5
alloc[P2][R3]: 4
alloc[P3][R0]: 0
alloc[P3][R1]: 6
alloc[P3][R2]: 3
alloc[P3][R3]: 2
alloc[P4][R0]: 0
alloc[P4][R1]: 0
alloc[P4][R2]: 1
alloc[P4][R3]: 4
Enter the Max Resources:
max[P0][R0]: 0
max[P0][R1]: 0
max[P0][R2]: 1
max[P0][R3]: 2
max[P1][R0]: 1
max[P1][R1]: 7
max[P1][R2]: 5
max[P1][R3]: 0
max[P2][R0]: 2
max[P2][R1]: 3
max[P2][R2]: 5
max[P2][R3]: 6
max[P3][R0]: 0
max[P3][R1]: 6
max[P3][R2]: 5
max[P3][R3]: 2
max[P4][R0]: 0
max[P4][R1]: 6
max[P4][R2]: 5
max[P4][R3]: 6
Enter the Available Resources:
avail[R0]: 1
avail[R1]: 5
avail[R2]: 2
avail[R3]: 0
Following is the SAFE Sequence
P0 -> P2 -> P3 -> P4 -> P1Theory:
Resource Allocation Graph (RAG) is a fundamental concept in operating systems and concurrent programming. It is used to represent the allocation of resources to processes and to detect and prevent deadlocks. It is a directed graph used to model the allocation of resources to processes in a system. It helps in visualizing the relationships between processes and resources and can be used to detect and prevent deadlocks.
One of the advantages of having a diagram is, sometimes it is possible to see a deadlock directly by using RAG, but then you might not be able to know that by looking at the table. But the tables are better if the system contains lots of process and resource and Graph is better if the system contains less number of process and resource. We know that any graph contains vertices and edges.
Types of Vertices in RAG: RAG also contains vertices and edges. In RAG vertices are two types and edges are also two types in RAG:
- Process Vertex: Every process will be represented as a process vertex. Generally, the process will be represented with a circle.
- Resource Vertex: Every resource will be represented as a resource vertex.
- Assign Edge: If you already assign a resource to a process then it is called Assign edge.
- Request Edge: It means in future the process might want some resource to complete the execution, that is called request edge.
Algorithm for check the deadlock:
- Step 1: First, find the currently available instances of each resource.
- Step 2: Check for each process which can be executed using the allocated + available resource.
- Step 3: Add the allocated resource of the executable process to the available resources and terminate it.
- Step 4: Repeat the 2nd and 3rd steps until the execution of each process.
- Step 5: If at any step, none of the processes can be executed then there is a deadlock in the system.
#include <stdio.h>
#include <stdbool.h>
#include <stdlib.h>
// Define the number of nodes in the graph
#define MAX_NODES 100
// Define the graph using an adjacency list
typedef struct Node
{
int vertex;
struct Node *next;
} Node;
Node *graph[MAX_NODES];
bool visited[MAX_NODES];
// Function to create a new node
Node *createNode(int v)
{
Node *newNode = (Node *)malloc(sizeof(Node));
newNode->vertex = v;
newNode->next = NULL;
return newNode;
}
// Function to add an edge to the graph
void addEdge(int from, int to)
{
Node *newNode = createNode(to);
newNode->next = graph[from];
graph[from] = newNode;
}
// Function to detect a cycle in the graph using DFS
bool isCyclicUtil(int node, bool *recStack)
{
if (visited[node] == false)
{
visited[node] = true;
recStack[node] = true;
Node *p = graph[node];
while (p != NULL)
{
if (visited[p->vertex] == false && isCyclicUtil(p->vertex, recStack))
return true;
else if (recStack[p->vertex] == true)
return true;
p = p->next;
}
}
recStack[node] = false;
return false;
}
// Function to check if the graph is cyclic
bool isCyclic()
{
bool *recStack = (bool *)malloc(MAX_NODES * sizeof(bool));
for (int i = 0; i < MAX_NODES; i++)
{
visited[i] = false;
recStack[i] = false;
}
for (int i = 0; i < MAX_NODES; i++)
if (isCyclicUtil(i, recStack))
return true;
return false;
}
int main()
{
int numProcesses, numResources, temp, resourceNumber;
// Get the number of resources and processes from the user
printf("Enter the number of resources: ");
scanf("%d", &numResources);
printf("Enter the number of processes: ");
scanf("%d", &numProcesses);
// Initialize the graph
for (int i = 0; i < numProcesses + numResources; i++)
graph[i] = NULL;
// Fill the graph with user input
for (int processIndex = 0; processIndex < numProcesses; processIndex++)
{
// Get the number of resources the current process is holding
printf("Enter the number of resources process %d is holding: ", processIndex);
scanf("%d", &temp);
for (int i = 0; i < temp; i++)
{
printf("Enter the resource number process %d is holding: ", processIndex);
scanf("%d", &resourceNumber);
// Add an edge from the resource to the process
addEdge(numProcesses + resourceNumber, processIndex);
}
// Get the number of resources the current process is requesting
printf("Enter the number of resources process %d is requesting: ", processIndex);
scanf("%d", &temp);
for (int i = 0; i < temp; i++)
{
printf("Enter the resource number process %d is requesting: ", processIndex);
scanf("%d", &resourceNumber);
// Add an edge from the process to the resource
addEdge(processIndex, numProcesses + resourceNumber);
}
}
// Check for deadlock
if (isCyclic())
printf("Deadlock detected!\n");
else
printf("No deadlock detected.\n");
return 0;
}Enter the number of resources: 2
Enter the number of processes: 2
Enter the number of resources process 0 is holding: 1
Enter the resource number process 0 is holding: 0
Enter the number of resources process 0 is requesting: 1
Enter the resource number process 0 is requesting: 1
Enter the number of resources process 1 is holding: 1
Enter the resource number process 1 is holding: 1
Enter the number of resources process 1 is requesting: 1
Enter the resource number process 1 is requesting: 0
Deadlock detected!Enter the number of resources: 2
Enter the number of processes: 3
Enter the number of resources process 0 is holding: 1
Enter the resource number process 0 is holding: 0
Enter the number of resources process 0 is requesting: 0
Enter the number of resources process 1 is holding: 1
Enter the resource number process 1 is holding: 1
Enter the number of resources process 1 is requesting: 0
Enter the number of resources process 2 is holding: 0
Enter the number of resources process 2 is requesting: 1
Enter the resource number process 2 is requesting: 0
No deadlock detected.- FIFO
- LRU
Theory:
Page replacement is basic to demand paging. It completes the separation between logical memory and physical memory. With this mechanism, an enormous virtual memory can be provided for programmers on a smaller physical memory. There are many different page-replacement algorithms. Every operating system probably has its own replacement scheme.
- FIFO: The FIFO algorithm is used in the paging method for memory management in an operating system that decides which existing page needs to be replaced in the queue. FIFO algorithm replaces the oldest (First) page which has been present for the longest time in the main memory. In simple words, when a new page comes in from secondary memory to main memory, It selects the front of the queue which is the oldest page present, and removes it.
Algorithm:
- Step 1: Start the program.
- Step 2: Read the number of frames.
- Step 3: Read the number of pages.
- Step 4: Read the page numbers.
- Step 5: Initialize the values in frames to -1.
- Step 6: Allocate the pages in to frames in First in first out order.
- Step 7: Display the number of page faults.
- Step 8: Stop the program.
#include <stdio.h>
int main()
{
int a[5], b[20], n, p = 0, q = 0, m = 0, h, k, i, q1 = 1;
char f = 'M';
printf("Enter the Number of Pages:");
scanf("%d", &n);
printf("Enter %d Page Numbers:\n", n);
for (i = 0; i < n; i++)
scanf("%d", &b[i]);
for (i = 0; i < n; i++)
{
if (p == 0)
{
if (q >= 3)
q = 0;
a[q] = b[i];
q++;
if (q1 < 3)
{
q1 = q;
}
}
printf("\n%d", b[i]);
printf("\t");
for (h = 0; h < q1; h++)
printf("%d-", a[h]);
if ((p == 0) && (q <= 3))
{
printf("-->%c", f);
m++;
}
p = 0;
for (k = 0; k < q1; k++)
{
if (b[i + 1] == a[k])
p = 1;
}
}
printf("\nNo of Miss:%d", m);
printf("\nNo of Hit:%d", n - m);
}Enter the Number of Pages:15
Enter 15 Page Numbers:
0
9
0
1
8
5
7
8
9
2
6
5
0
7
4
0 0--->M
9 0-9--->M
0 0-9-
1 0-9-1--->M
8 8-9-1--->M
5 8-5-1--->M
7 8-5-7--->M
8 8-5-7-
9 9-5-7--->M
2 9-2-7--->M
6 9-2-6--->M
5 5-2-6--->M
0 5-0-6--->M
7 5-0-7--->M
4 4-0-7--->M
No of Miss:13
No of Hit:2- LRU: LRU stands for Least Recently Used. As the name suggests, this algorithm is based on the strategy that whenever a page fault occurs, the least recently used page will be replaced with a new page. So, the page not utilized for the longest time in memory (compared to all other pages) gets replaced. This strategy is known as LRU paging.
Algorithm:
- Step 1: Start the program.
- Step 2: Read the number of frames.
- Step 3: Read the number of pages.
- Step 4: Read the page numbers.
- Step 5: Initialize the values in frames to -1.
- Step 6: Allocate the pages in to frames by selecting the page that has not been used for the longest period of time.
- Step 7: Display the number of page faults.
- Step 8: Stop the program.
#include <stdio.h>
int main()
{
int a[5], b[20], p = 0, q = 0, m = 0, h, k,
i, q1 = 1, j, u, n;
char f = 'M';
printf("Enter the number of pages:");
scanf("%d", &n);
printf("Enter %d Page Numbers:\n", n);
for (i = 0; i < n; i++)
scanf("%d", &b[i]);
for (i = 0; i < n; i++)
{
if (p == 0)
{
if (q >= 3)
q = 0;
a[q] = b[i];
q++;
if (q1 < 3)
{
q1 = q;
}
}
printf("\n%d", b[i]);
printf("\t");
for (h = 0; h < q1; h++)
printf("%d-", a[h]);
if ((p == 0) && (q <= 3))
{
printf("-->%c", f);
m++;
}
p = 0;
if (q1 == 3)
{
for (k = 0; k < q1; k++)
{
if (b[i + 1] == a[k])
p = 1;
}
for (j = 0; j < q1; j++)
{
u = 0;
k = i;
while (k >= (i - 1) && (k >= 0))
{
if (b[k] == a[j])
u++;
k--;
}
if (u == 0)
q = j;
}
}
else
{
for (k = 0; k < q; k++)
{
if (b[i + 1] == a[k])
p = 1;
}
}
}
printf("\nNo of Miss:%d", m);
printf("\nNo of Hit:%d", n - m);
}Enter the number of pages:15
Enter 15 Page Numbers:
0
9
0
1
8
0
2
7
1
3
2
9
8
5
2
0 0--->M
9 0-9--->M
0 0-9-
1 0-9-1--->M
8 0-8-1--->M
0 0-8-1-
2 0-8-2--->M
7 0-7-2--->M
1 1-7-2--->M
3 1-7-3--->M
2 1-2-3--->M
9 9-2-3--->M
8 9-2-8--->M
5 9-5-8--->M
2 2-5-8--->M
No of Miss:13
No of Hit:2- FCFS (First Come First Serve)
- SSTF (Shortest Seek Time Fit)
Theory:
Disk scheduling is a technique operating system use to manage the order in which disk I/O (input/output) requests are processed. Disk scheduling is also known as I/O Scheduling. Disk scheduling algorithms are crucial in managing how data is read from and written to a computer's hard disk.
Common disk scheduling methods include First-Come, First-Served (FCFS), Shortest Seek Time First (SSTF), SCAN, C-SCAN, LOOK, and C-LOOK.
- FCFS: FCFS (First Come First Serve) is the simplest disk scheduling algorithm. This algorithm entertains requests in the order they arrive in the disk queue. The algorithm looks very fair and there is no starvation (all requests are serviced sequentially) but generally, it does not provide the fastest service.
Algorithm
- Step 1: Let Request array represents an array storing indexes of tracks that have been requested in ascending order of their time of arrival.
headis the position of disk head. - Step 2: Let us one by one take the tracks in default order and calculate the absolute distance of the track from the head.
- Step 3: Increment the total seek count with this distance.
- Step 4: Currently serviced track position now becomes the new head position.
- Step 5: Go to Step 2 until all tracks in request array have not been serviced.
#include <stdio.h>
#include <stdlib.h>
#define MAX_QUEUE_SIZE 20
int main()
{
int queue[MAX_QUEUE_SIZE];
int n, head, i, seek = 0, max;
float avg;
printf("Enter the max range of the disk: ");
if (scanf("%d", &max) != 1 || max <= 0)
{
fprintf(stderr, "Invalid max range. Please enter a positive integer.\n");
return 1;
}
printf("Enter the size of the queue request (max %d): ", MAX_QUEUE_SIZE - 1);
if (scanf("%d", &n) != 1 || n <= 0 || n >= MAX_QUEUE_SIZE)
{
fprintf(stderr, "Invalid queue size. Please enter a positive integer less than %d.\n",
MAX_QUEUE_SIZE);
return 1;
}
printf("Enter the queue of disk positions to be read:\n");
for (i = 1; i <= n; i++)
{
if (scanf("%d", &queue[i]) != 1 || queue[i] < 0 || queue[i] > max)
{
fprintf(stderr, "Invalid disk position. Please enter a value between 0 and %d.\n", max);
return 1;
}
}
printf("Enter the initial head position: ");
if (scanf("%d", &head) != 1 || head < 0 || head > max)
{
fprintf(stderr, "Invalid initial head position. Please enter a value between 0 and %d.\n", max);
return 1;
}
queue[0] = head;
for (i = 0; i < n; i++)
{
int diff = abs(queue[i + 1] - queue[i]);
seek += diff;
printf("Disk head moves from %d to %d with seek %d\n", queue[i], queue[i + 1], diff);
}
printf("Total seek time is %d\n", seek);
avg = (float)seek / n;
printf("Average seek time is %.2f\n", avg);
return 0;
}Enter the max range of the disk: 100
Enter the size of the queue request (max 19): 9
Enter the queue of disk positions to be read:
45
20
90
5
30
35
25
70
95
Enter the initial head position: 49
Disk head moves from 49 to 45 with seek 4
Disk head moves from 45 to 20 with seek 25
Disk head moves from 20 to 90 with seek 70
Disk head moves from 90 to 5 with seek 85
Disk head moves from 5 to 30 with seek 25
Disk head moves from 30 to 35 with seek 5
Disk head moves from 35 to 25 with seek 10
Disk head moves from 25 to 70 with seek 45
Disk head moves from 70 to 95 with seek 25
Total seek time is 294
Average seek time is 32.67- SSTF: SSTF (Shortest Seek Time Fist) is an abbreviation that selects the request which is closest to the current head position before moving the head away to service other requests. This is done by selecting the request which has the least seek time from the current head position.
Algorithm
- Step 1: Let the Request array represents an array storing indexes of tracks that have been requested.
headis the position of the disk head. - Step 2: Find the positive distance of all tracks in the request array from the head.
- Step 3: Find a track from the requested array which has not been accessed/serviced yet and has a minimum distance from the head.
- Step 4: Increment the total seek count with this distance.
- Step 5: Currently serviced track position now becomes the new head position.
- Step 6: Go to step 2 until all tracks in the request array have not been serviced.
#include <stdio.h>
#include <stdlib.h>
int main()
{
int RQ[100], i, n, TotalHeadMoment = 0, initial, count = 0;
float m;
printf("Enter the number of Requests:");
scanf("%d", &n);
printf("Enter the Requests sequence:\n");
for (i = 0; i < n; i++)
scanf("%d", &RQ[i]);
printf("Enter initial head position:");
scanf("%d", &initial);
while (count != n)
{
int min = 1000, d, index;
for (i = 0; i < n; i++)
{
d = abs(RQ[i] - initial);
if (min > d)
{
min = d;
index = i;
}
}
TotalHeadMoment = TotalHeadMoment + min;
initial = RQ[index];
RQ[index] = 1000;
count++;
}
printf("Total Seek Time is %d \n", TotalHeadMoment);
m = (float)TotalHeadMoment / n;
printf("Average Seek Time is %.2f", m);
return 0;
}Enter the number of Requests:10
Enter the Requests sequence:
45
20
90
10
15
25
66
78
76
23
Enter initial head position:51
Total Seek Time is 121
Average Seek Time is 12.10Theory: The producer-consumer problem is an example of a multi-process synchronization problem. The problem describes two processes, the producer and the consumer that share a common fixed-size buffer and use it as a queue. The producer's job is to generate data, put it into the buffer, and start again. At the same time, the consumer is consuming the data (i.e., removing it from the buffer), one piece at a time.
What is the Actual Problem?
Given the common fixed-size buffer, the task is to make sure that the producer can't add data into the buffer when it is full and the consumer can't remove data from an empty buffer. Accessing memory buffers should not be allowed to producers and consumers at the same time.
Approach: The idea is to use the concept of parallel programming and Critical Section to implement the Producer-Consumer problem in C language using OpenMP.
#include <stdio.h>
void main()
{
int buffer[10], bufsize, in, out, produce, consume, choice = 0;
in = 0;
out = 0;
bufsize = 5;
while (choice != 3)
{
printf("1. Produce \t 2. Consume\t3. Exit");
printf("\nEnter your choice: ");
scanf("%d", &choice);
switch (choice)
{
case 1:
if ((in + 1) % bufsize == out)
printf("Buffer is Full\n");
else
{
printf("Enter the value: ");
scanf("%d", &produce);
buffer[in] = produce;
in = (in + 1) % bufsize;
}
break;
case 2:
if (in == out)
printf("Buffer is Empty\n");
else
{
consume = buffer[out];
printf("The consumed value is %d\n", consume);
out = (out + 1) % bufsize;
}
break;
}
}
}1. Produce 2. Consume 3. Exit
Enter your choice: 1
Enter the value: 43
1. Produce 2. Consume 3. Exit
Enter your choice: Enter the value: 432
1. Produce 2. Consume 3. Exit
Enter your choice: 2
The consumed value is 43
1. Produce 2. Consume 3. Exit
Enter your choice: 43
1. Produce 2. Consume 3. Exit
Enter your choice: 43
1. Produce 2. Consume 3. Exit
Enter your choice: 2
The consumed value is 432
1. Produce 2. Consume 3. Exit
Enter your choice: 2
Buffer is Empty
1. Produce 2. Consume 3. Exit
Enter your choice: 1
Enter the value: 345
1. Produce 2. Consume 3. Exit
Enter your choice: 1
Enter the value: 567
1. Produce 2. Consume 3. Exit
Enter your choice: 1
Enter the value: 324
1. Produce 2. Consume 3. Exit
Enter your choice: 1
Enter the value: 324
1. Produce 2. Consume 3. Exit
Enter your choice: 1
Buffer is Full
1. Produce 2. Consume 3. Exit
Enter your choice: 345
1. Produce 2. Consume 3. Exit
Enter your choice: 2
The consumed value is 345
1. Produce 2. Consume 3. Exit
Enter your choice: 2
The consumed value is 567
1. Produce 2. Consume 3. Exit
Enter your choice: 23
1. Produce 2. Consume 3. Exit
Enter your choice: 44
1. Produce 2. Consume 3. Exit
Enter your choice: 2
The consumed value is 324
1. Produce 2. Consume 3. Exit
Enter your choice: 3- Worst-Fit
- Best-Fit
- First-Fit
Theory:
Contiguous memory allocation is a memory allocation strategy. As the name implies, we utilize
this technique to assign contiguous blocks of memory to each task. Thus, whenever a process
asks to access the main memory, we allocate a continuous segment from the empty region to the
process based on its size.
- First- Fit: The first-fit algorithm searches for the first free partition that is large enough to accommodate the process. The operating system starts searching from the beginning of the memory and allocates the first free partition that is large enough to fit the process.
#include <stdio.h>
#include <process.h>
void main()
{
int a[20], p[20], i, j, n, m;
printf("Enter no of Blocks: ");
scanf("%d", &n);
printf("Enter the Block size:\n");
for (i = 1; i <= n; i++)
{
scanf("%d", &a[i]);
}
printf("Enter no. of Process: ");
scanf("%d", &m);
printf("Enter the size of Processes:\n");
for (i = 1; i <= m; i++)
{
scanf("%d", &p[i]);
}
for (i = 1; i <= n; i++)
{
for (j = 1; j <= m; j++)
{
if (p[j] <= a[i])
{
printf("The Process %d allocated to %d\n", j, a[i]);
p[j] = 10000;
break;
}
}
}
for (j = 1; j <= m; j++)
{
if (p[j] != 10000)
{
printf("The Process %d is not allocated\n", j);
}
}
}Enter no of Blocks: 5
Enter the Block size:
100
500
200
300
600
Enter no. of Process: 4
Enter the size of Processes:
212
417
112
426
The Process 1 allocated to 500
The Process 3 allocated to 200
The Process 2 allocated to 600
The Process 4 is not allocated - Best- Fit: The best-fit algorithm searches for the smallest free partition that is large enough to accommodate the process. The operating system searches the entire memory and selects the free partition that is closest in size to the process.
#include <stdio.h>
#include <conio.h>
#define max 25
int main()
{
int frag[max], b[max], f[max], i, j, nb, nf, temp, lowest = 10000;
static int bf[max], ff[max];
printf("\nEnter the number of blocks: ");
scanf("%d", &nb);
printf("Enter the number of files: ");
scanf("%d", &nf);
printf("Enter the size of the blocks:-\n");
for (i = 1; i <= nb; i++)
{
printf("Block %d: ", i);
scanf("%d", &b[i]);
}
printf("Enter the size of the files :-\n");
for (i = 1; i <= nf; i++)
{
printf("File %d: ", i);
scanf("%d", &f[i]);
}
for (i = 1; i <= nf; i++)
{
for (j = 1; j <= nb; j++)
{
if (bf[j] != 1)
{
temp = b[j] - f[i];
if (temp >= 0)
if (lowest > temp)
{
ff[i] = j;
lowest = temp;
}
}
}
frag[i] = lowest;
bf[ff[i]] = 1;
lowest = 10000;
}
printf("\nFile No\t\tFile Size\tBlock No\tBlock Size\tFragment");
for (i = 1; i <= nf && ff[i] != 0; i++)
printf("\n%d\t\t%d\t\t%d\t\t%d\t\t%d", i, f[i], ff[i], b[ff[i]], frag[i]);
return 0;
}Enter the number of blocks: 5
Enter the number of files: 4
Enter the size of the blocks:-
Block 1: 100
Block 2: 500
Block 3: 200
Block 4: 300
Block 5: 600
Enter the size of the files :-
File 1: 212
File 2: 417
File 3: 112
File 4: 426
File No File Size Block No Block Size Fragment
1 212 4 300 88
2 417 2 500 83
3 112 3 200 88
4 426 5 600 174 - Worst- Fit: The worst-fit algorithm searches for the largest free partition and allocates the process to it. This algorithm is designed to leave the largest possible free partition for future use.
#include <stdio.h>
#include <stdlib.h>
int disk[20];
struct blocks
{
int bid;
int size;
int index;
} block;
struct processs
{
int pid;
int size;
int flag;
struct blocks b;
int fragment;
} process;
int main()
{
int nb, np, i, j;
int disk_index = 0;
printf("Total disk size is 50.\n");
printf("Enter the number of blocks: ");
scanf("%d", &nb);
struct blocks bls[nb], temp;
for (i = 0; i < nb; i++)
{
bls[i].bid = i;
printf("Enter the size of block %d : ", i);
scanf("%d", &bls[i].size);
bls[i].index = disk_index;
disk_index = disk_index + bls[i].size;
}
printf("Enter the number of processes: ");
scanf("%d", &np);
struct processs ps[np];
for (i = 0; i < np; i++)
{
ps[i].pid = i;
printf("Enter the size of process %d : ", i);
scanf("%d", &ps[i].size);
ps[i].flag = -1;
}
for (i = 0; i < nb - 1; i++)
{
for (j = i + 1; j < nb; j++)
{
if (bls[j].size > bls[i].size)
{
temp.bid = bls[j].bid;
temp.size = bls[j].size;
temp.index = bls[j].index;
bls[j].bid = bls[i].bid;
bls[j].size = bls[i].size;
bls[j].index = bls[i].index;
bls[i].bid = temp.bid;
bls[i].size = temp.size;
bls[i].index = temp.index;
}
}
}
for (i = 0; i < np; i++)
{
if (i >= nb || bls[i].size < ps[i].size)
printf("No block is available for the process\n");
else
ps[i].b = bls[i];
}
printf("Now process block allocation list is\n");
for (i = 0; i < np; i++)
{
printf("process id: %d process size %d block id %d free space %d.\n",
ps[i].pid, ps[i].size, ps[i].b.bid, ps[i].b.size - ps[i].size);
}
return 0;
}Total disk size is 50.
Enter the number of blocks: 4
Enter the size of block 0 : 10
Enter the size of block 1 : 9
Enter the size of block 2 : 4
Enter the size of block 3 : 8
Enter the number of processes: 3
Enter the size of process 0 : 1
Enter the size of process 1 : 2
Enter the size of process 2 : 3
Now process block allocation list is
process id: 0 process size 1 block id 0 free space 9.
process id: 1 process size 2 block id 1 free space 7.
process id: 2 process size 3 block id 3 free space 5.See Also: Operating System